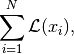pixyz.losses (Loss API)¶
Loss¶
Negative expected value of log-likelihood (entropy)¶
CrossEntropy¶
![-\mathbb{E}_{q(x)}[\log p(x)] \approx -\frac{1}{L}\sum_{l=1}^L \log p(x_l),](_images/math/38ddb09b7cb885a22f4010a128786958799cba1e.png)
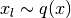 .
.Entropy¶
![-\mathbb{E}_{p(x)}[\log p(x)] \approx -\frac{1}{L}\sum_{l=1}^L \log p(x_l),](_images/math/339b559b8c1496eb8db139f6a53beb0b20c1e421.png)
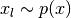 .
.StochasticReconstructionLoss¶
-
class
pixyz.losses.StochasticReconstructionLoss(encoder, decoder, input_var=None)[source]¶ Bases:
pixyz.losses.losses.LossReconstruction Loss (Monte Carlo approximation).
![-\mathbb{E}_{q(z|x)}[\log p(x|z)] \approx -\frac{1}{L}\sum_{l=1}^L \log p(x|z_l),](_images/math/707fa4489d409200b3fbe6ded73cd394ad1aa235.png)
where
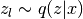 .
.- Note:
- This class is a special case of the CrossEntropy class. You can get the same result with CrossEntropy.
-
loss_text¶
Negative log-likelihood¶
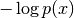
Lower bound¶
![\mathbb{E}_{q(z|x)}[\log \frac{p(x,z)}{q(z|x)}] \approx \frac{1}{L}\sum_{l=1}^L \log p(x, z_l),](_images/math/e2f9c94a8d8135a6c511f6fe7d231d8c6cac7a17.png)
Divergence¶
![D_{KL}[p||q] = \mathbb{E}_{p(x)}[\log \frac{p(x)}{q(x)}]](_images/math/7da88e47e8c39de2bec91f9449e75e1e56bfaeda.png)
Similarity¶
SimilarityLoss¶
-
class
pixyz.losses.SimilarityLoss(p1, p2, input_var=None, var=['z'], margin=0)[source]¶ Bases:
pixyz.losses.losses.LossLearning Modality-Invariant Representations for Speech and Images (Leidai et. al.)
Adversarial loss (GAN loss)¶
AdversarialJensenShannon¶
![D_{JS}[p(x)||q(x)] \leq 2 \cdot D_{JS}[p(x)||q(x)] + 2 \log 2
= \mathbb{E}_{p(x)}[\log d^*(x)] + \mathbb{E}_{q(x)}[\log (1-d^*(x))],](_images/math/39deab6cf70e24d0d737baa91aff3d971db218b0.png)
![d^*(x) = \arg\max_{d} \mathbb{E}_{p(x)}[\log d(x)] + \mathbb{E}_{q(x)}[\log (1-d(x))]](_images/math/08bd6dc585dcdcb77beb4ac7120aba79a8e85298.png) .
.AdversarialKullbackLeibler¶
![D_{KL}[q(x)||p(x)] = \mathbb{E}_{q(x)}[\log \frac{q(x)}{p(x)}]
= \mathbb{E}_{q(x)}[\log \frac{d^*(x)}{1-d^*(x)}],](_images/math/c8976e83a61814386f59403647ec1fdbb78bd06a.png)
![W(p, q) = \sup_{||d||_{L} \leq 1} \mathbb{E}_{p(x)}[d(x)] - \mathbb{E}_{q(x)}[d(x)]](_images/math/76b508ff5d13d253e543ab112662841e28f09d32.png)
Auto-regressive loss¶
ARLoss¶
-
class
pixyz.losses.ARLoss(step_loss, last_loss=None, step_fn=<function ARLoss.<lambda>>, max_iter=1, return_params=False, input_var=None, series_var=None, update_value=None)[source]¶ Bases:
pixyz.losses.losses.LossAuto-regressive loss.
This loss performs “scan”-like operation. You can implement arbitrary auto-regressive models with this class.
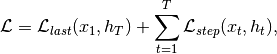
where
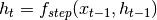 .
.-
loss_text¶
-
![\mathbb{E}_{p_{data}(x)}[\mathcal{L}(x)] \approx \frac{1}{N}\sum_{i=1}^N \mathcal{L}(x_i),](_images/math/bf9d0a7488a0627d93f1206e1cac8c049f816a51.png)
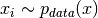 and
and 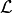 is a loss function.
is a loss function.