pixyz.distributions (Distribution API)¶
Distribution¶
-
class
pixyz.distributions.distributions.Distribution(cond_var=[], var=['x'], name='p', dim=1)[source]¶ Bases:
torch.nn.modules.module.ModuleDistribution class. In pixyz, all distributions are required to inherit this class.
- var : list
- Variables of this distribution.
- cond_var : list
- Conditional variables of this distribution. In case that cond_var is not empty, we must set the corresponding inputs in order to sample variables or estimate the log likelihood.
- dim : int
- Number of dimensions of this distribution. This might be ignored depending on the shape which is set in the sample method and on its parent distribution. Moreover, this is not consider when this class is inherited by DNNs. This is set to 1 by default.
- name : str
- Name of this distribution. This name is displayed in prob_text and prob_factorized_text. This is set to “p” by default.
-
distribution_name¶
-
name¶
-
var¶
-
cond_var¶
-
input_var¶ Normally, input_var has same values as cond_var.
-
prob_text¶
-
prob_factorized_text¶
-
get_params(params_dict={})[source]¶ This method aims to get parameters of this distributions from constant parameters set in initialization and outputs of DNNs.
- params_dict : dict
- Input parameters.
- output_dict : dict
- Output parameters
>>> print(dist_1.prob_text, dist_1.distribution_name) p(x) Normal >>> dist_1.get_params() {"loc": 0, "scale": 1} >>> print(dist_2.prob_text, dist_2.distribution_name) p(x|z) Normal >>> dist_1.get_params({"z": 1}) {"loc": 0, "scale": 1}
-
sample(x={}, shape=None, batch_size=1, return_all=True, reparam=False)[source]¶ Sample variables of this distribution. If cond_var is not empty, we should set inputs as a dictionary format.
- x : torch.Tensor, list, or dict
- Input variables.
- shape : tuple
- Shape of samples. If set, batch_size and dim are ignored.
- batch_size : int
- Batch size of samples. This is set to 1 by default.
- return_all : bool
- Choose whether the output contains input variables.
- reparam : bool
- Choose whether we sample variables with reparameterized trick.
- output : dict
- Samples of this distribution.
-
log_likelihood(x_dict)[source]¶ Estimate the log likelihood of this distribution from inputs formatted by a dictionary.
- x_dict : dict
- Input samples.
- log_like : torch.Tensor
- Log-likelihood.
Exponential families¶
Normal¶
Bernoulli¶
RelaxedBernoulli¶
-
class
pixyz.distributions.RelaxedBernoulli(temperature, cond_var=[], var=['x'], name='p', dim=None, **kwargs)[source]¶ Bases:
pixyz.distributions.distributions.DistributionBase-
distribution_name¶
-
FactorizedBernoulli¶
Categorical¶
RelaxedCategorical¶
-
class
pixyz.distributions.RelaxedCategorical(temperature, cond_var=[], var=['x'], name='p', dim=None, **kwargs)[source]¶ Bases:
pixyz.distributions.distributions.DistributionBase-
distribution_name¶
-
Complex distributions¶
MixtureModel¶
-
class
pixyz.distributions.MixtureModel(distributions, prior, name='p')[source]¶ Bases:
pixyz.distributions.distributions.DistributionMixture models.
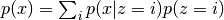
- distributions : list
- List of distributions.
- prior : pixyz.Distribution.Categorical
- Prior distribution of latent variable (i.e., the contribution rate). This should be a categorical distribution and the number of its category should be the same as the length of the distribution list.
>>> from pixyz.distributions import Normal, Categorical >>> from pixyz.distributions.mixture_distributions import MixtureModel >>> >>> z_dim = 3 # the number of mixture >>> x_dim = 2 # the input dimension. >>> >>> distributions = [] # the list of distributions >>> for i in range(z_dim): >>> loc = torch.randn(x_dim) # initialize the value of location (mean) >>> scale = torch.empty(x_dim).fill_(1.) # initialize the value of scale (variance) >>> distributions.append(Normal(loc=loc, scale=scale, var=["x"], name="p_%d" %i)) >>> >>> probs = torch.empty(z_dim).fill_(1. / z_dim) # initialize the value of probabilities >>> prior = Categorical(probs=probs, var=["z"], name="prior") >>> >>> p = MixtureModel(distributions=distributions, prior=prior)
-
prob_text¶
-
prob_factorized_text¶
-
distribution_name¶
-
sample(batch_size=1, return_hidden=False, **kwargs)[source]¶ Sample variables of this distribution. If cond_var is not empty, we should set inputs as a dictionary format.
- x : torch.Tensor, list, or dict
- Input variables.
- shape : tuple
- Shape of samples. If set, batch_size and dim are ignored.
- batch_size : int
- Batch size of samples. This is set to 1 by default.
- return_all : bool
- Choose whether the output contains input variables.
- reparam : bool
- Choose whether we sample variables with reparameterized trick.
- output : dict
- Samples of this distribution.
Estimate joint log-likelihood, log p(x, z), where input is x.
- x_dict : dict
- Input variables (including var).
- loglike : torch.Tensor
- dim=0 : the number of mixture dim=1 : the size of batch
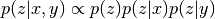
Special distributions¶
Deterministic¶
-
class
pixyz.distributions.Deterministic(**kwargs)[source]¶ Bases:
pixyz.distributions.distributions.DistributionDeterministic distribution (or degeneration distribution)
-
distribution_name¶
-
sample(x={}, return_all=True, **kwargs)[source]¶ Sample variables of this distribution. If cond_var is not empty, we should set inputs as a dictionary format.
- x : torch.Tensor, list, or dict
- Input variables.
- shape : tuple
- Shape of samples. If set, batch_size and dim are ignored.
- batch_size : int
- Batch size of samples. This is set to 1 by default.
- return_all : bool
- Choose whether the output contains input variables.
- reparam : bool
- Choose whether we sample variables with reparameterized trick.
- output : dict
- Samples of this distribution.
-
DataDistribution¶
-
class
pixyz.distributions.DataDistribution(var, name='p_data')[source]¶ Bases:
pixyz.distributions.distributions.DistributionData distribution. TODO: Fix this behavior if multiplied with other distributions
-
distribution_name¶
-
sample(x={}, **kwargs)[source]¶ Sample variables of this distribution. If cond_var is not empty, we should set inputs as a dictionary format.
- x : torch.Tensor, list, or dict
- Input variables.
- shape : tuple
- Shape of samples. If set, batch_size and dim are ignored.
- batch_size : int
- Batch size of samples. This is set to 1 by default.
- return_all : bool
- Choose whether the output contains input variables.
- reparam : bool
- Choose whether we sample variables with reparameterized trick.
- output : dict
- Samples of this distribution.
-
input_var¶ In DataDistribution, input_var is same as var.
-
Flow-based¶
PlanarFlow¶
RealNVP¶
-
class
pixyz.distributions.RealNVP(prior, dim, num_multiscale_layers=2, var=[], image=False, name='p', **kwargs)[source]¶ Bases:
pixyz.distributions.distributions.Distribution-
prob_text¶
-
forward(x, inverse=False, jacobian=False)[source]¶ When this class is inherited by DNNs, it is also intended that this method is overrided.
-
sample(x={}, only_flow=False, return_all=True, **kwargs)[source]¶ Sample variables of this distribution. If cond_var is not empty, we should set inputs as a dictionary format.
- x : torch.Tensor, list, or dict
- Input variables.
- shape : tuple
- Shape of samples. If set, batch_size and dim are ignored.
- batch_size : int
- Batch size of samples. This is set to 1 by default.
- return_all : bool
- Choose whether the output contains input variables.
- reparam : bool
- Choose whether we sample variables with reparameterized trick.
- output : dict
- Samples of this distribution.
-
Operators¶
ReplaceVarDistribution¶
-
class
pixyz.distributions.distributions.ReplaceVarDistribution(a, replace_dict)[source]¶ Bases:
pixyz.distributions.distributions.DistributionReplace names of variables in Distribution.
- a : pixyz.Distribution (not pixyz.MultiplyDistribution)
- Distribution.
- replace_dict : dict
- Dictionary.
-
forward(*args, **kwargs)[source]¶ When this class is inherited by DNNs, it is also intended that this method is overrided.
-
get_params(params_dict)[source]¶ This method aims to get parameters of this distributions from constant parameters set in initialization and outputs of DNNs.
- params_dict : dict
- Input parameters.
- output_dict : dict
- Output parameters
>>> print(dist_1.prob_text, dist_1.distribution_name) p(x) Normal >>> dist_1.get_params() {"loc": 0, "scale": 1} >>> print(dist_2.prob_text, dist_2.distribution_name) p(x|z) Normal >>> dist_1.get_params({"z": 1}) {"loc": 0, "scale": 1}
-
sample(x={}, shape=None, batch_size=1, return_all=True, reparam=False)[source]¶ Sample variables of this distribution. If cond_var is not empty, we should set inputs as a dictionary format.
- x : torch.Tensor, list, or dict
- Input variables.
- shape : tuple
- Shape of samples. If set, batch_size and dim are ignored.
- batch_size : int
- Batch size of samples. This is set to 1 by default.
- return_all : bool
- Choose whether the output contains input variables.
- reparam : bool
- Choose whether we sample variables with reparameterized trick.
- output : dict
- Samples of this distribution.
-
log_likelihood(x)[source]¶ Estimate the log likelihood of this distribution from inputs formatted by a dictionary.
- x_dict : dict
- Input samples.
- log_like : torch.Tensor
- Log-likelihood.
-
input_var¶ Normally, input_var has same values as cond_var.
-
distribution_name¶
MarginalizeVarDistribution¶
-
class
pixyz.distributions.distributions.MarginalizeVarDistribution(a, marginalize_list)[source]¶ Bases:
pixyz.distributions.distributions.DistributionMarginalize variables in Distribution.
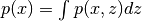
- a : pixyz.Distribution (not pixyz.DistributionBase)
- Distribution.
- marginalize_list : list
- Variables to marginalize.
-
forward(*args, **kwargs)[source]¶ When this class is inherited by DNNs, it is also intended that this method is overrided.
-
get_params(params_dict)[source]¶ This method aims to get parameters of this distributions from constant parameters set in initialization and outputs of DNNs.
- params_dict : dict
- Input parameters.
- output_dict : dict
- Output parameters
>>> print(dist_1.prob_text, dist_1.distribution_name) p(x) Normal >>> dist_1.get_params() {"loc": 0, "scale": 1} >>> print(dist_2.prob_text, dist_2.distribution_name) p(x|z) Normal >>> dist_1.get_params({"z": 1}) {"loc": 0, "scale": 1}
-
sample(x={}, shape=None, batch_size=1, return_all=True, reparam=False)[source]¶ Sample variables of this distribution. If cond_var is not empty, we should set inputs as a dictionary format.
- x : torch.Tensor, list, or dict
- Input variables.
- shape : tuple
- Shape of samples. If set, batch_size and dim are ignored.
- batch_size : int
- Batch size of samples. This is set to 1 by default.
- return_all : bool
- Choose whether the output contains input variables.
- reparam : bool
- Choose whether we sample variables with reparameterized trick.
- output : dict
- Samples of this distribution.
-
log_likelihood(x_dict)[source]¶ Estimate the log likelihood of this distribution from inputs formatted by a dictionary.
- x_dict : dict
- Input samples.
- log_like : torch.Tensor
- Log-likelihood.
-
input_var¶ Normally, input_var has same values as cond_var.
-
distribution_name¶
-
prob_factorized_text¶
MultiplyDistribution¶
-
class
pixyz.distributions.distributions.MultiplyDistribution(a, b)[source]¶ Bases:
pixyz.distributions.distributions.DistributionMultiply by given distributions, e.g,
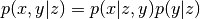 .
In this class, it is checked if two distributions can be multiplied.
.
In this class, it is checked if two distributions can be multiplied.p(x|z)p(z|y) -> Valid
p(x|z)p(y|z) -> Valid
p(x|z)p(y|a) -> Valid
p(x|z)p(z|x) -> Invalid (recursive)
p(x|z)p(x|y) -> Invalid (conflict)
- a : pixyz.Distribution
- Distribution.
- b : pixyz.Distribution
- Distribution.
>>> p_multi = MultipleDistribution([a, b]) >>> p_multi = a * b
-
inh_var¶
-
input_var¶ Normally, input_var has same values as cond_var.
-
prob_factorized_text¶
-
sample(x={}, shape=None, batch_size=1, return_all=True, reparam=False)[source]¶ Sample variables of this distribution. If cond_var is not empty, we should set inputs as a dictionary format.
- x : torch.Tensor, list, or dict
- Input variables.
- shape : tuple
- Shape of samples. If set, batch_size and dim are ignored.
- batch_size : int
- Batch size of samples. This is set to 1 by default.
- return_all : bool
- Choose whether the output contains input variables.
- reparam : bool
- Choose whether we sample variables with reparameterized trick.
- output : dict
- Samples of this distribution.