pixyz.losses (Loss API)¶
Loss¶
Negative expected value of log-likelihood (entropy)¶
CrossEntropy¶
![H[p||q] = -\mathbb{E}_{p(x)}[\log q(x)] \approx -\frac{1}{L}\sum_{l=1}^L \log q(x_l),](_images/math/f1af856e4e7f9801101bfd47b7c26060a693f328.png)
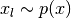 .
.Entropy¶
![H[p] = -\mathbb{E}_{p(x)}[\log p(x)] \approx -\frac{1}{L}\sum_{l=1}^L \log p(x_l),](_images/math/21d19f0cfd38c91f12ffa2ac9d50f67042b52dda.png)
StochasticReconstructionLoss¶
![-\mathbb{E}_{q(z|x)}[\log p(x|z)] \approx -\frac{1}{L}\sum_{l=1}^L \log p(x|z_l),](_images/math/707fa4489d409200b3fbe6ded73cd394ad1aa235.png)
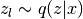 .
.LossExpectation¶
Lower bound¶
![\mathbb{E}_{q(z|x)}[\log \frac{p(x,z)}{q(z|x)}] \approx \frac{1}{L}\sum_{l=1}^L \log p(x, z_l),](_images/math/e2f9c94a8d8135a6c511f6fe7d231d8c6cac7a17.png)
Statistical distance¶
KullbackLeibler¶
-
class
pixyz.losses.KullbackLeibler(p, q, input_var=None, dim=None)[source]¶ Bases:
pixyz.losses.losses.LossKullback-Leibler divergence (analytical).
![D_{KL}[p||q] = \mathbb{E}_{p(x)}[\log \frac{p(x)}{q(x)}]](_images/math/7da88e47e8c39de2bec91f9449e75e1e56bfaeda.png)
- TODO: This class seems to be slightly slower than this previous implementation
- (perhaps because of set_distribution).
-
loss_text¶
WassersteinDistance¶
-
class
pixyz.losses.WassersteinDistance(p, q, metric=PairwiseDistance(), input_var=None)[source]¶ Bases:
pixyz.losses.losses.LossWasserstein distance.
![W(p, q) = \inf_{\Gamma \in \mathcal{P}(x_p\sim p, x_q\sim q)} \mathbb{E}_{(x_p, x_q) \sim \Gamma}[d(x_p, x_q)]](_images/math/ffe52a4f83e762b329ce01c9e40a3970fdea6de7.png)
However, instead of the above true distance, this class computes the following one.
![W'(p, q) = \mathbb{E}_{x_p\sim p, x_q \sim q}[d(x_p, x_q)].](_images/math/114d1c08cc49f55c03d3f6e02f3d1b99839c0c40.png)
Here,
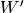 is the upper of
is the upper of 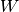 (i.e.,
(i.e., 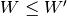 ), and these are equal when both
), and these are equal when both 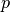 and
and 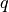 are degenerate (deterministic) distributions.
are degenerate (deterministic) distributions.-
loss_text¶
-
MMD¶
-
class
pixyz.losses.MMD(p, q, input_var=None, kernel='gaussian', **kernel_params)[source]¶ Bases:
pixyz.losses.losses.LossThe Maximum Mean Discrepancy (MMD).
![D_{MMD^2}[p||q] = \mathbb{E}_{p(x), p(x')}[k(x, x')] + \mathbb{E}_{q(x), q(x')}[k(x, x')]
- 2\mathbb{E}_{p(x), q(x')}[k(x, x')]](_images/math/4d6ab2e5bede99f83af1b9495221f4e554a39e29.png)
where
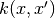 is any positive definite kernel.
is any positive definite kernel.-
loss_text¶
-
Adversarial statistical distance (GAN loss)¶
AdversarialJensenShannon¶
![D_{JS}[p(x)||q(x)] \leq 2 \cdot D_{JS}[p(x)||q(x)] + 2 \log 2
= \mathbb{E}_{p(x)}[\log d^*(x)] + \mathbb{E}_{q(x)}[\log (1-d^*(x))],](_images/math/39deab6cf70e24d0d737baa91aff3d971db218b0.png)
![d^*(x) = \arg\max_{d} \mathbb{E}_{p(x)}[\log d(x)] + \mathbb{E}_{q(x)}[\log (1-d(x))]](_images/math/08bd6dc585dcdcb77beb4ac7120aba79a8e85298.png) .
.AdversarialKullbackLeibler¶
![D_{KL}[p(x)||q(x)] = \mathbb{E}_{p(x)}[\log \frac{p(x)}{q(x)}]
= \mathbb{E}_{p(x)}[\log \frac{d^*(x)}{1-d^*(x)}],](_images/math/d70d68138b0aa518954b9f8b61a4df0f365dbccf.png)
![d^*(x) = \arg\max_{d} \mathbb{E}_{q(x)}[\log d(x)] + \mathbb{E}_{p(x)}[\log (1-d(x))]](_images/math/c88b276c8780b91b02b8c9a9cdcaf8e9742297da.png) .
.![W(p, q) = \sup_{||d||_{L} \leq 1} \mathbb{E}_{p(x)}[d(x)] - \mathbb{E}_{q(x)}[d(x)]](_images/math/76b508ff5d13d253e543ab112662841e28f09d32.png)
Loss for sequential distributions¶
IterativeLoss¶
-
class
pixyz.losses.IterativeLoss(step_loss, max_iter=1, input_var=None, series_var=None, update_value={}, slice_step=None, timestep_var=['t'])[source]¶ Bases:
pixyz.losses.losses.LossIterative loss.
This class allows implementing an arbitrary model which requires iteration (e.g., auto-regressive models).
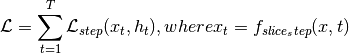
-
loss_text¶
-
Loss for special purpose¶
Parameter¶
-
class
pixyz.losses.losses.Parameter(input_var)[source]¶ Bases:
pixyz.losses.losses.Loss-
loss_text¶
-
Operators¶
LossOperator¶
LossSelfOperator¶
AddLoss¶
-
class
pixyz.losses.losses.AddLoss(loss1, loss2)[source]¶ Bases:
pixyz.losses.losses.LossOperator-
loss_text¶
-
SubLoss¶
-
class
pixyz.losses.losses.SubLoss(loss1, loss2)[source]¶ Bases:
pixyz.losses.losses.LossOperator-
loss_text¶
-
MulLoss¶
-
class
pixyz.losses.losses.MulLoss(loss1, loss2)[source]¶ Bases:
pixyz.losses.losses.LossOperator-
loss_text¶
-
DivLoss¶
-
class
pixyz.losses.losses.DivLoss(loss1, loss2)[source]¶ Bases:
pixyz.losses.losses.LossOperator-
loss_text¶
-
NegLoss¶
-
class
pixyz.losses.losses.NegLoss(loss1)[source]¶ Bases:
pixyz.losses.losses.LossSelfOperator-
loss_text¶
-
AbsLoss¶
-
class
pixyz.losses.losses.AbsLoss(loss1)[source]¶ Bases:
pixyz.losses.losses.LossSelfOperator-
loss_text¶
-
BatchMean¶
-
class
pixyz.losses.losses.BatchMean(loss1)[source]¶ Bases:
pixyz.losses.losses.LossSelfOperatorLoss averaged over batch data.
![\mathbb{E}_{p_{data}(x)}[\mathcal{L}(x)] \approx \frac{1}{N}\sum_{i=1}^N \mathcal{L}(x_i),](_images/math/bf9d0a7488a0627d93f1206e1cac8c049f816a51.png)
where
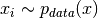 and
and 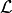 is a loss function.
is a loss function.-
loss_text¶
-
BatchSum¶
-
class
pixyz.losses.losses.BatchSum(loss1)[source]¶ Bases:
pixyz.losses.losses.LossSelfOperatorLoss summed over batch data.
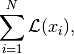
where
and is a loss function.-
loss_text¶
-